Genetic Code: Definition, Steps, Types and Examples
Genetic Code definition: The genetic code is the set of instructions in DNA and RNA that determines how proteins are made in living organisms. It consists of codons, sequences of three nucleotides, each coding for a specific amino acid. This code is universal, redundant, and unambiguous, ensuring accurate protein synthesis. In this article, genetic code, basic concepts of genetic code, the transcription process, the translation process, properties of the genetic code, and exceptions to the genetic code are discussed. Genetic code is a topic of the chapter Molecular Basis of Inheritance in Biology.
NEET 2025: Mock Test Series | Syllabus | High Scoring Topics | PYQs
NEET Important PYQ's Subject wise: Physics | Chemistry | Biology
New: Meet Careers360 B.Tech/NEET Experts in your City | Book your Seat now
- What is a Genetic Code?
- Characteristics of Genetic Code
- Transcription Process
- Translation Process
- Properties of the Genetic Code
- Exceptions to the Genetic Code
- Applications of Knowing the Genetic Code

What is a Genetic Code?
The genetic code is a set of rules by which information that is encoded in the genetic material, either DNA or RNA sequences, is translated into proteins by living cells. This language is universal in guiding the synthesis of proteins, the building blocks of life, from information contained in genes. The genetic code is known to be core biology and heredity because it speaks about how the transfer of information from one generation to another takes place genetically and how it promotes the structure and function of proteins.

Diagram of Genetic Code
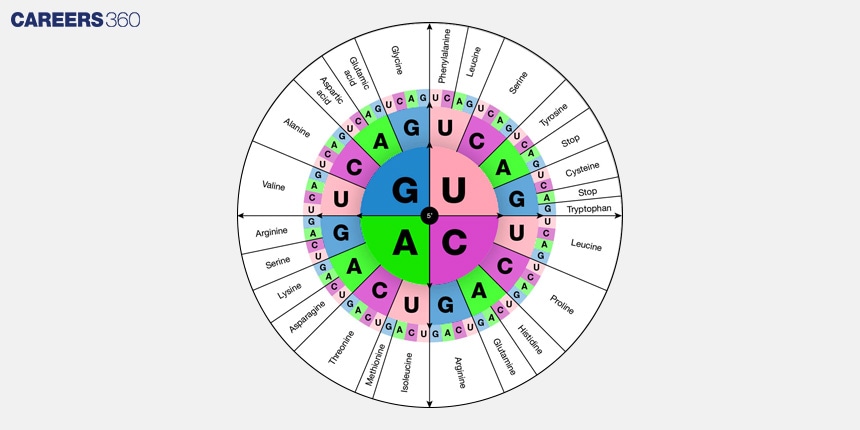
Decoding the genetic code is truly one of the milestones of molecular biology. James Watson and Francis Crick explained the DNA double helix in 1953, doing much to help our understanding of genetics. In 1961, Marshall Nirenberg and Heinrich Matthaei discovered the first codon. Other scientists performed experiments that soon revealed the remaining genetic code.
Several Nobel Prizes have been awarded for work on the genetic code. In 1962, Watson, Crick, and Maurice Wilkins were awarded the Nobel Prize in Physiology or Medicine for their discovery that identified the molecular structure of nucleic acids. In 1968, Nirenberg, Robert Holley, and Har Gobind Khorana were awarded Nobel Prizes for their interpretation of the genetic code and its function in protein synthesis.
Characteristics of Genetic Code
Some basic concepts are as follows:
DNA and RNA Basics
DNA is deoxyribonucleic acid, and RNA is ribonucleic acid. These are nucleic acids that store and transmit genetic information. DNA is a double-stranded molecule that acts as a long-term storage, whereas RNA is mostly single-stranded; it works both as a messenger and functional molecule in protein synthesis.
Nucleotides and Bases
Nucleotides are the basic building blocks of nucleic acids. Each nucleotide is made up of a sugar, phosphate group, and nitrogenous base. For DNA bases, there are adenine (A), thymine (T), cytosine (C), and guanine (G). In RNA, uracil replaces thymine.
Codons and Anticodons
A codon is a series of three nucleotides in the mRNA that code for a specific amino acid or an amino acid termination signal during protein synthesis. The sequence complementary to the codon on the tRNA molecule--the anticodon--guarantees that the correct amino acid is brought into the sequence of the growing polypeptide chain.
Also Read-
Transcription Process
Transcription is a process wherein the transfer of the genetic code in DNA gets copied into mRNA. The RNA polymerase binds to DNA and synthesizes a complementary RNA strand. Such formed mRNAs take the carried genetic information out of the nucleus to the ribosomes, where the process of protein synthesis takes place.
Translation Process
Translation is the process through which mRNA gets converted to a protein. The sequence of mRNA is read in codons by the ribosomes while the appropriate amino acids are brought to the ribosome by tRNA molecules. These amino acids get assembled into a polypeptide chain by the ribosome and fold into a functional protein.
Properties of the Genetic Code
The major properties of the genetic code are:
Triplet code
A collection of nucleotides that form an amino acid is called a codon. Strong evidence supports the idea that a triplet—a sequence of three nucleotides—codes for an amino acid in a protein.
Three-base codons are created using the four nucleotide bases, namely A, G, C, and U. Codons, which specify amino acids, are among the 64 codons. Since each codon for an amino acid indicates that there are many codes for the same amino acid, there are 64 codons for 20 amino acids.
Universality
This roughly universal genetic code means that the same codons would come to specify the same amino acids in almost all species. This universality also led to the hypothesis regarding a common origin of life.
Degeneracy
The genetic code is degenerate, meaning multiple codons code for the same amino acid. It is this redundancy that protects against mutations: some changes in the DNA sequence do not alter the resulting protein.
Non-Overlapping and Commaless
The reading of genetic code occurs in a continuous, nonoverlapping fashion, without spacing or punctuation marks thereby separating codons from one another. This was a mechanism to ensure perfect and efficient translations of mRNAs at all times into proteins.
Polarity
Every triplet is read from 5' → 3', with the starting base being 5', the middle base coming next, and the final base being 3'. This suggests that codons have a fixed polarity, meaning that if they were read in the opposite manner, their base sequence would flip and designate two distinct proteins.
Start and Stop Codons
The start codon is often the AUG codon. Eukaryotes (methionine) or prokaryotes (N-formylmethionine) are the starting points for the polypeptide chain. Conversely, UAG, UAA, and UGA are referred to as stop codons or termination codons. These never code for any amino acids and are not read by any tRNA molecules.
Exceptions to the Genetic Code
Since most genes in plants and microbes have comparable START and STOP signals and similar codons assigned to identical amino acids, the genetic code is universal. Assigning one or two of the STOP codons to an amino acid is one of the few exceptions that have been found.
In addition, even though GUG is designed for valine, both AUG and GUG may code for methionine as a beginning codon. This violates the non-ambiguousness property. As a result, it can be claimed that few codes frequently deviate from universal or unambiguous codes.
Applications of Knowing the Genetic Code
Advances in understanding the genetic code have prompted radical technologies like CRISPR, which enables very high-precision editing of genes. This makes several applications possible within agriculture—in GMOs—and medicine for the creation of new treatments but more generally in industry, notably for the production of biofuels and bioplastics.
Medical and Clinical Studies
The knowledge of the genetic code plays a vital role in comprehending genetic diseases and designing gene therapies. Gene therapy is essentially treating or preventing diseases by correcting a gene when it is malfunctioning. It gives hope for some disease conditions that are incurable at present.
Also Read-
| Process of Translation in Biology | Gene Regulation and Gene Expression |
| Genes | Genetic Code And Mutation |
| Gene to Protein - Transcription and Translation | Protein Synthesis |
Recommended Video for Genetic Code
Frequently Asked Questions (FAQs)
The genetic code denotes a set of rules whereby translation from DNA or RNA sequences occurs into proteins. Proteins are essential for all biological functions and operations, and thus their synthesis is crucial.
A codon is a three-nucleotide-segment sequence of mRNA specifying an amino acid. A corresponding complementary three-nucleotide segment on tRNA pairing with the codon during translation is called the anticodon.
Transcription has to do with copying DNA into mRNA, while translation decodes mRNA into protein. These two processes have been inherent in gene expression and protein synthesis.
The mutation changes the DNA sequence, and this change of sequence can result in an effect on the genetic code. It can affect the structure and function of proteins, including some diseases; other mutations, however, make no difference.
These involve gene editing technologies like CRISPR, the development of gene therapies, the production of genetically modified organisms, pharmaceuticals, and industrial biotechnology.
Also Read
29 Nov'24 09:31 AM
19 Nov'24 09:26 AM
18 Nov'24 06:45 PM
18 Nov'24 09:29 AM
18 Nov'24 09:18 AM
18 Nov'24 09:01 AM
18 Nov'24 08:37 AM
16 Nov'24 03:45 PM
Articles

Student Community: Where Questions Find Answers